Automation Anywhere's IQ Bot and UIPath's Document Understanding are software offerings that these companies are positioning as extensions to their base RPA solutions.
3 minute read
June 6, 2020
These products are examples of a fairly crowded software space called Intelligent Document Processing (IDP). One of the research companies out there defines Intelligent Document Processing (IDP) as any software product or solution that captures data from documents (e.g., email, text, PDF and scanned documents), categorizes, and extracts relevant data for further processing using AI technologies such as computer vision, OCR, Natural Language Processing (NLP), and machine learning.
As it relates to process automation solutions, IDP software is definitely adjacent to RPA and BPA, since those technologies require structured data, but many of the inputs come in the form of semi-structured or maybe even unstructured documents.
From a marketing standpoint, RPA vendors love their IDP software since it's a way to bring AI into the mix, which certainly has a nice cachet. That said, IDP software has a very targeted set of use cases and should not be considered a general solution for automating all types of cognitive activities.
IDP Workflow
In general, the workflows for most IDP solutions are very similar. From an end-to-end perspective, they all start with either structured PDFs or images (which could be embedded in PDFs), and they output structured data. Each step is important in order to maximize the accuracy of the results.
Pre-processing - Documents typically can exist in varying levels of quality, which can impact the results of data extraction. The pre-processing step improves the quality of the documents by applying techniques such as noise reduction, binarization, de-skewing, and more.
Classification - Documents can contain multiple pages with different formats. Intelligent document classification uses AI-based technologies to automatically classify and separate multipage documents to pull out the relevant pages of information before extraction.
Extraction - This step involves OCR to digitize documents and then leveraging one or more extractors to extract specific data. Typically, IDP solutions include a library of pre-trained extraction models, which are pre-populated with the right fields for extraction. The relevant information is extracted from the document(s) before it is validated for accuracy. Typical types of extractors are:
RegEx Based Extractor - relies on regular expressions to extract the information and works for data that appears in very similar textual contexts across documents.
Form Extractor - functions based on the rules and templates and can process structured documents, tables, and checkboxes.
ML Extractors - machine learning models used for processing less structured documents with varying layouts, that are semi-structured documents. Different vendors may offer different pre-trained domain-specific ML extractors. Also, it may be necessary to retrain extractors based on the specific data being put through them.
Validation - Once data is extracted a combination of automated and human validation can be used to improve the quality of the results.
Automated Validation - ensure extracted fields meet confidence thresholds, execution of predefined rules, and basic exception handling.
Human Validation - when needed, a human can check in to confirm or correct the extracted data or handle more complex exceptions. Ideally, output from the human validation should not only correct the data extracted from an individual document but those corrections should be fed back to improve the extraction algorithm.
Vendors
The market is pretty flooded with IDP software. Here are some of the products we've run across.
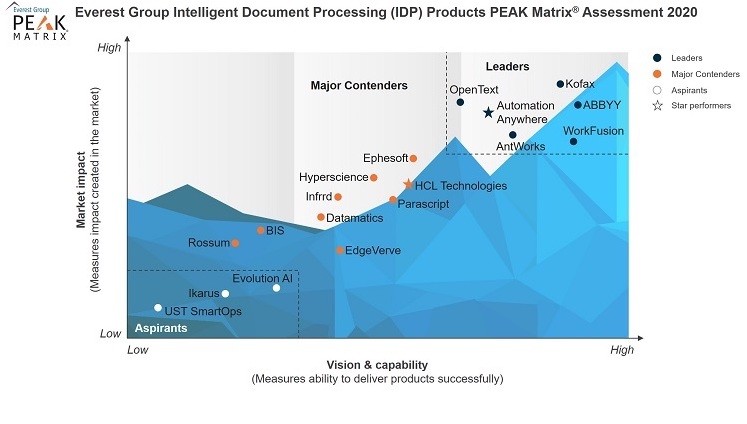
Here is a comparison of IDP software that was put out by the Everest Group (https://www.workfusion.com/reports/everest-group-idp-peak-matrix-2020/). One of the interesting things to note here is that Automation Anywhere has moved up to the Leaders in 2020 from sort of midfield in 2019. Also, what's interesting is that neither UIPath nor IBM's Datacap show up here. I suppose, as with all of these research firms, not showing up in an assessment doesn't necessarily mean they are not a player, it could simply be that they didn't pay the research company to be on their list. But who knows?
Conclusion
Extracting data from semi-structured documents is a use case that seems to show up in a lot of our automation projects, especially RPA. Based on the IDP software offerings, it seems like a problem that has been solved over and over again. One thing that I've noticed, however, is that whether you use a pre-packaged IDP solution like IQ Bot, or basically roll your own by putting expression parsing logic directly in your bot, it's never going to be perfect; at least not for long. PDF structures may be inconsistent, or change over time. So putting regex parsing logic in your bot can lead to broken bots. IDP software doesn't always get it right the first time. So if you're going to use it, you have to use the whole IDP workflow, including the human validation and correction components. In either case, setting the customer's expectations up front is key since it impacts the software they will have to license, the robustness of the solution, and potentially how the end-user will interact with the solution.